Qwen3.5-35B-A3B#
Info
Qwen3.5 系列终于发布了小杯模型,对应的在阿里云提供 API,Qwen3.5-Plus 即 Qwen3.5-397B-A17B,Qwen3.5-Flash 即 Qwen3.5-35B-A3B。
前面几天对于 Qwen3.5-Plus 的表现,网友评论都是不错、那么这个小杯表现如何是我们比较关注的,毕竟一点资源就能跑起来了。
Qwen3.5 Usage Guide - vLLM Recipes
Qwen/Qwen3.5-35B-A3B · Hugging Face
服务器信息:
显示已折叠代码(29 行)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| 【CPU 信息】
CPU 型号: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
CPU 核心数: 32
【系统版本】
操作系统: Ubuntu
版本: 22.04.5 LTS (Jammy Jellyfish)
内核版本: 5.15.0-168-generic
【GPU 信息】
NVIDIA GPU 检测到:
GPU 0: NVIDIA GeForce RTX 3090
显存: 24576 MiB
驱动版本: 580.126.09
GPU 1: NVIDIA GeForce RTX 3090
显存: 24576 MiB
驱动版本: 580.126.09
GPU 2: NVIDIA GeForce RTX 3090
显存: 24576 MiB
驱动版本: 580.126.09
GPU 3: NVIDIA GeForce RTX 3090
显存: 24576 MiB
驱动版本: 580.126.09
GPU 4: NVIDIA GeForce RTX 3090
显存: 24576 MiB
驱动版本: 580.126.09
CUDA 版本:
13.0
|
按照官方文档 安装最新的 vLLM,使用 vLLM 部署qwen3.5-35b-a3b,(我习惯使用 vLLM,好用、性能也很好)
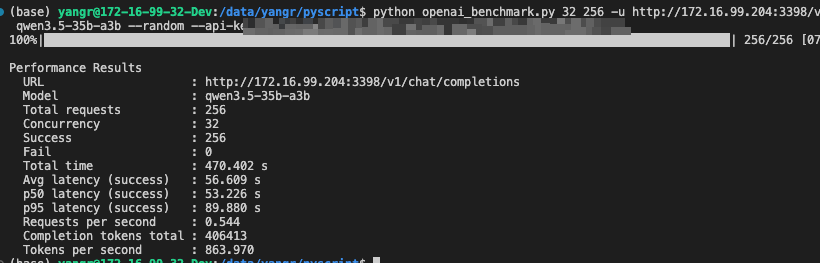
根据我的显卡资源情况,保守估计,调整 tp size 并行跑在 4 张卡上、max-model-len 设置为 128k,也是官方表示的最低限制。并发最高 32
1
| vllm serve /data/huggingface_model/Qwen/Qwen3.5-35B-A3B --served-model-name qwen3.5-35b-a3b --port 13538 --tensor-parallel-size 4 --max-model-len 128000 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder --gpu-memory-utilization 0.85 --max_num_seqs 32
|
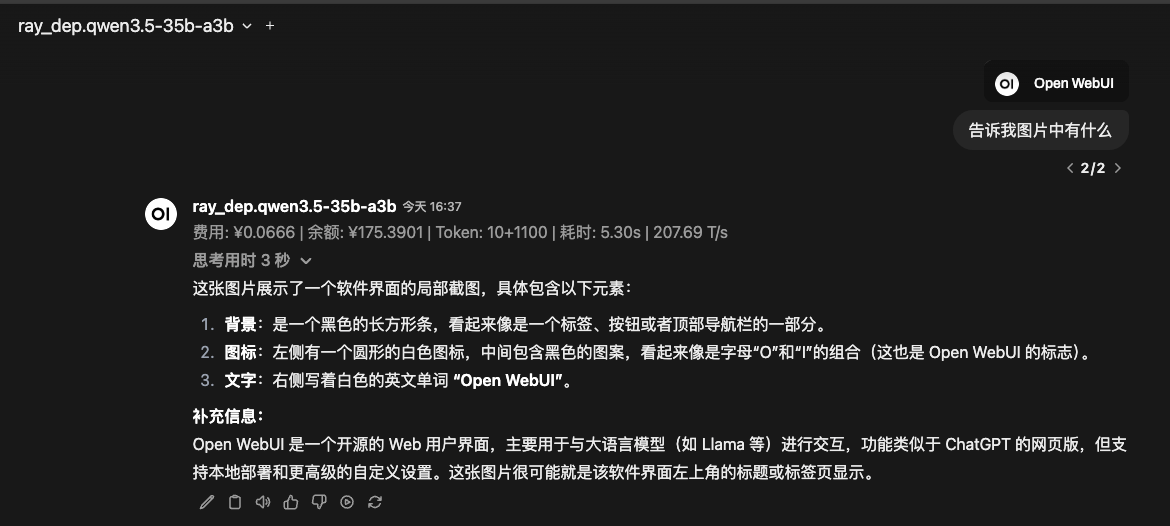
单请求输出速度 200+Tokens/S ,且原生支持多模态
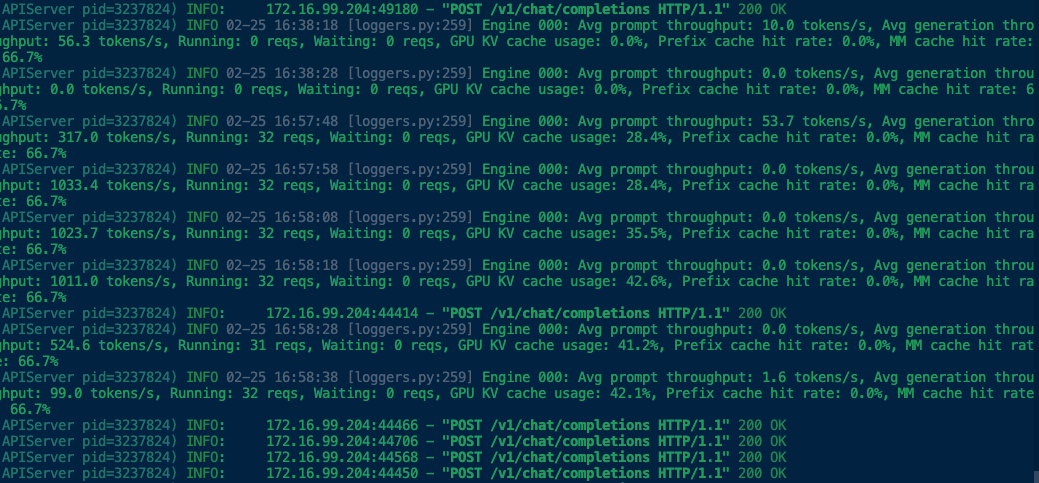
之前写的小脚本测一下32个并发下简单问题输出情况
符合预期,MOE 模型的吞吐还是很满意的,但是这个思考不知道是否可开关,以及还有一个 27B 的 Dense 模型理论上应该更聪明。打算后续接入 openClaw 测试一下效果。