昨天刷到一个 AI 移动硬盘的广告,结合前段时间老板和我说的 AI NAS,本来没怎么放在心上,因为我本身不会是前者的客户,后者又不是小公司能做的,不过整理硬件的时候,发现一个 Frefly 的 RK3588 盒子,灵机一动、RK3588 有 NPU,理论肯定有人做这个端侧LLM 的推理。
AI 移动硬盘 比如一个相册管理器。照片都在本地,模型在本地看图、打标签、生成描述、回答“帮我找去年海边那张有红色帐篷的照片”之类的问题。隐私不出设备,速度也足够交互。这个方向如果成立,小模型就不是“缩水版云模型”,而是一个很适合本地数据管理的入口。
话不多说,现成的代码开始一键运行。
硬件和模型
板子信息:
| 项目 | 配置 |
|---|---|
| 板子 | Firefly AIO-3588L |
| SoC | RK3588 |
| 内存 | 8GB |
| 系统 | Ubuntu 22.04.5 |
| Kernel | 6.1.118 |
| NPU driver | 0.9.8 |
模型选的是已经转换好的 RKLLM/RKNN 版本:
| 文件 | 作用 | 大小 |
|---|---|---|
qwen3-vl-2b-instruct_w8a8_rk3588.rkllm | LLM decoder | 约 2.3GB |
qwen3-vl-2b_vision_rk3588.rknn | vision encoder | 约 812MB |
| 空间占用如下 |
| |
第一版:能跑,但速度不对劲
最开始我用官方 multimodal C++ demo 包了一层 FastAPI,再写了一个简单网页。网页支持:
- 文本对话。
- 上传图片识图。
- SSE 流式输出。
- 显示 decode tokens/s、prefill tokens/s、内存占用和总耗时。
第一版能跑起来,但速度看起来只有 7 tokens/s 左右。
因为我看 RKLLM 官方 benchmark 里,RK3588 上 Qwen3-VL-2B w8a8 的 multimodal decode 大约是 14.91 tokens/s,image encoder 大约 2.08s。如果我这里只有 7 tokens/s,还有不少优化空间。
优化路线
把 RKLLM 线程绑到 RK3588 的 A76 大核:
| |
初始状态下,CPU governor 是 interactive,空闲时只有 408MHz;DDR 是 dmc_ondemand,空闲时 528MHz;GPU 也是低频。NPU 虽然已经在 950MHz,但 LLM decode 并不是“只有 NPU 干活”。CPU 唤醒、采样、回调、内存带宽都会影响每 token 间隔。
我做了一个 boost_perf.sh 调整运行频率:
这一步之后,速度明显上去了。禁用 CPU idle 是一个很小但有效的点:decode 是很多小步串起来的,每 token 之间 CPU 如果频繁进出低功耗状态,尾延迟会抖。
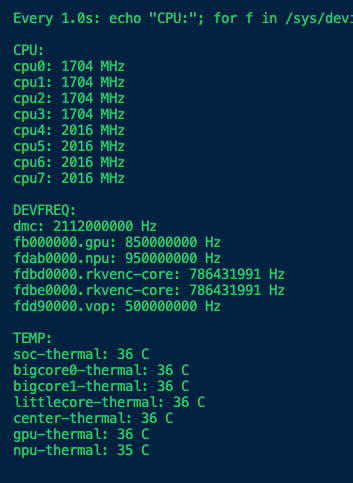
除此之外的一些改动其实没什么太大的提升,以及,我自己的统计逻辑也优化一下哈哈哈
Web 层:一个“进程包装版”的 ChatWeb
先用 FastAPI 每次请求启动一次官方 demo:
| |
这版的好处是简单、稳定、容易复现。坏处也很明显:每次请求都会重新加载 LLM 和 vision encoder,所以首 token 延迟大概 5 到 6 秒。
页面如下
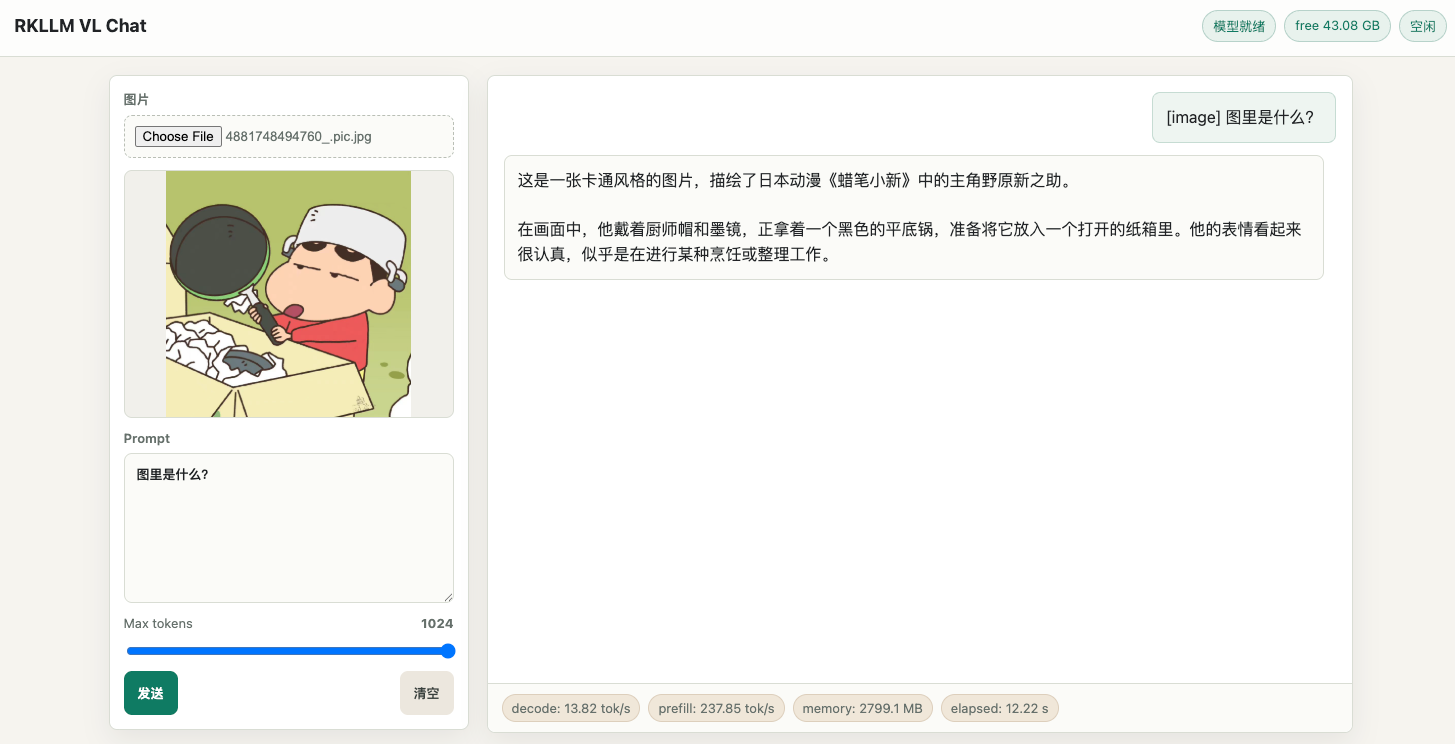
最后的速度
最后的实测结果:
| 场景 | decode 速度 |
|---|---|
| CLI 文本短样本 | 14.3 到 14.4 tok/s |
| CLI 图像短样本 | 13.8 到 14.0 tok/s |
| CLI 文本强制长样本 | 14.29 tok/s |
| CLI 图像强制长样本 | 13.84 tok/s |
| Web SSE 文本请求 | 14.24 tok/s |
| Web 上传图片识图 | 13.81 tok/s |
图像 encoder 大约 2.1s。Web 冷启动总耗时大约 7 到 8 秒。
这个结果基本接近 RKLLM benchmark 里 Qwen3-VL-2B 在 RK3588 上的 14.91 tok/s。
那接着优化就是模型常驻,去掉 python 层等等等等。
端侧 Agent 也许越来越近了
部署完这个,内存上也有余量:系统空闲时可用内存约 6GB,Qwen3-VL 当前推理内存约 2.8GB。再放一个小 embedding 模型是现实的。那么本地 RAG 实际也能理论闭环了,甚至如果你用大点内存,还能塞下 ASR 和 TTS。
14 tokens/s 看起来比较慢其实也还好,因为不是 coding agent 场景,不需要高频次输出大量内容,体感上来讲可以做比较丝滑的交互不至于很折磨人。
把它放到“相册管理”、本地小型知识库等等,确实有可行性
参考链接
官方/一手资料
- Rockchip RKLLM 官方仓库
- RKLLM benchmark
- RKLLM multimodal demo
- RKLLM server demo
- Rockchip RKNN Toolkit 2
- Qwen3-VL 模型集合
- Qwen3-VL-2B-Instruct 官方模型
- Qwen3-VL-Embedding-2B
- Firefly AIO-3588L 官方产品页
- Firefly Core-3588L Wiki
转换模型/社区参考
- GatekeeperZA/Qwen3-VL-2B-Instruct-RKLLM
- JiahaoLi/Qwen3-VL-RK3588
- Qengineering/Qwen3-VL-2B-NPU
- Radxa RKLLM 安装文档
我这套源码应该没啥用,大家的文档都很清楚了。