agent 发展到现在,已经有很多成熟的方案了,但是为了更高的设计一致性和项目掌握度,需要从 0-1 设计一套。期间会借鉴参考很多开源项目。项目全程遵循 KISS 原则。
概念和技术栈选择
查了一下 agent 的概念其实比较久远,很早以前的经典理论我们不提,本文只针对目前的 生成式 AI 所代表的 agent。
对于 agent 的执行机制,你可能听说过 ReAct (reasoning and acting)ReAct 来自 2022 年论文《ReAct: Synergizing Reasoning and Acting in Language Models》1,概念如下
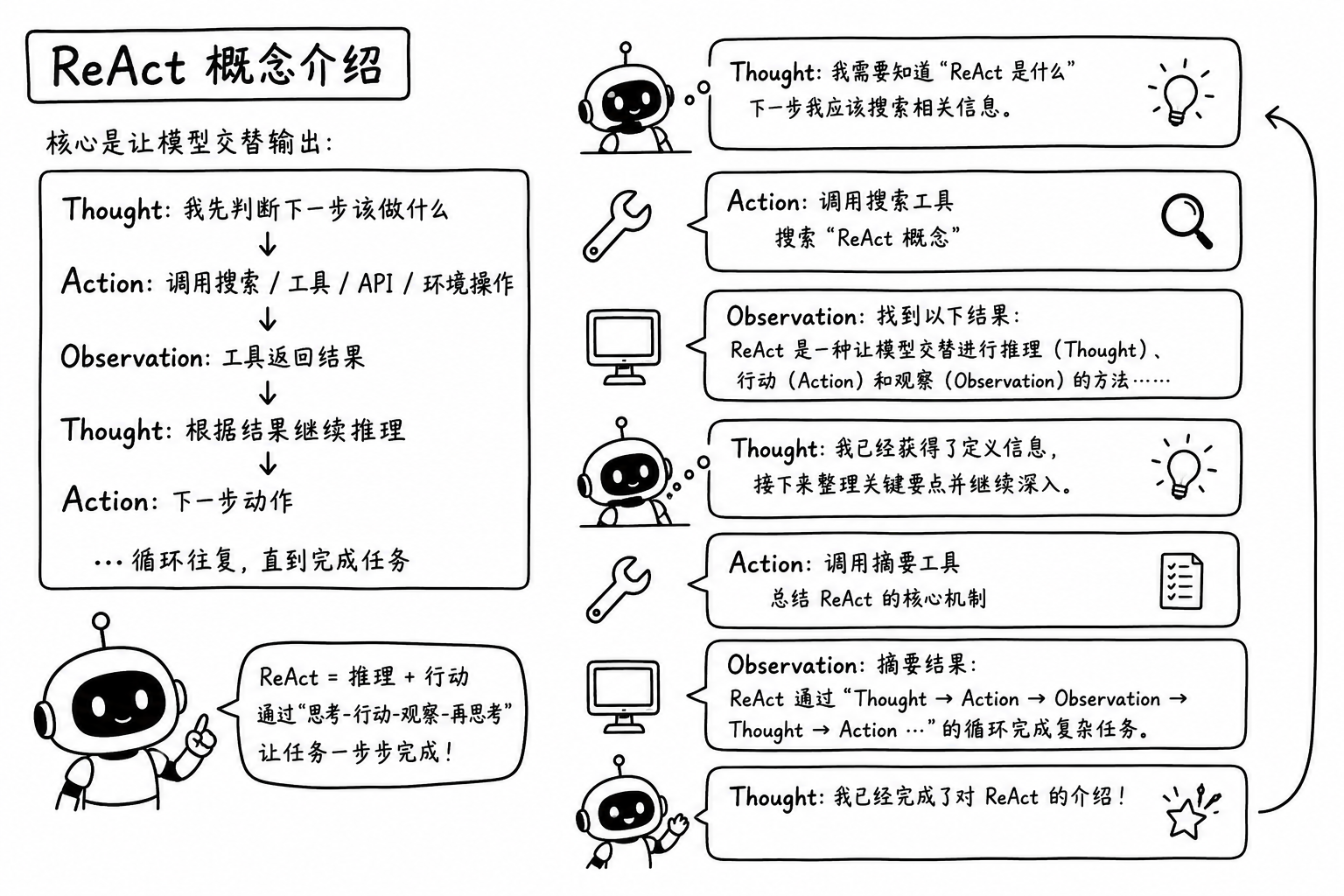
可以说这是 agent 最基本和常见的执行框架,属于评估优化式的架构,也就是通过迭代反馈不断改进输出来逼近目标。
而在两年前还有一些 workflow 产品比如扣子、dify 等,也常被误称为 agent/智能体。但其实他们还是链式处理任务的工作流为主。
我定义智能体的一个核心边界就是他能自己决定使用什么工具以及怎么使用。
截止到开始本项目之前,市面上已经有了很多类似产品,各有特色,但是最底层的原理还是一样的。现在需要在一些业务场景用到或者开发一个平台来提供 agent 服务,所以需要从自构建开始保证设计的一致性和对系统的了解性。
在技术栈的选择上,选择全力投入 python,如果熟悉 python 语法,借助 python 的生态。开发agent 的 MVP 将降低很多心智负担,但是显而易见的缺点是对底层控制降低(比如一些隐形的 runtime error 和性能消耗),但是个人判断,结合我的技术栈掌握和现处公司项目的情况,我决定第一个发行版本将全量使用 python 构建,后续选择使用 Rust 语言作为 热点模块 的替换直至开发团队掌握 rust 技术栈后进行全量重构。(如果这个项目胎死腹中也无需谈什么未来。)
架构设计
基于 ReAct 架构设计的基础思路
还是比较容易的,这里参考王二老师的文章,列一些功能和设计思路。2
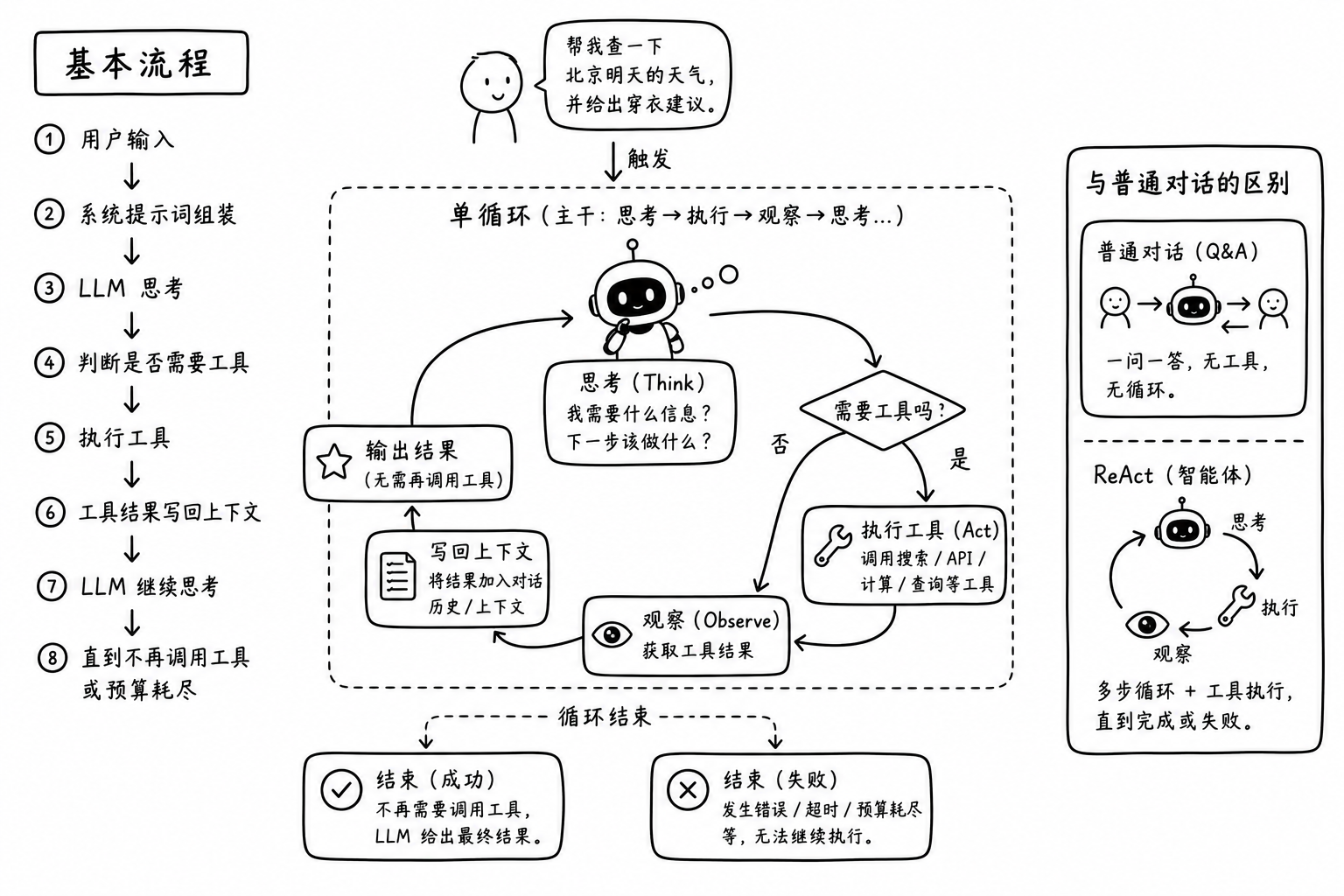
基本流程:
用户输入 -> 系统提示词组装 -> LLM 思考 -> 判断是否需要工具 -> 执行工具 -> 工具结果写回上下文 -> LLM 继续思考 -> 直到不再调用工具或预算耗尽
由 用户输入触发这个单循环。主干就是 思考->执行->观察->思考…
和原本的对话交互的区别就是加上一个循环。 循环结束 要么是不需要调用工具了,模型会给到结果,要么是 出错了
消息协议
很好理解,只要你调用过 openai 范式的 chatcompletions 接口就会知道消息列表里面有四个角色
system / user / assistant / tool
系统提示词分层设计
这样可以动态组合针对不同的场景和需求 比如可以分成:
- 身份层:你是谁,比如编程 Agent
- 工具层:有哪些工具,每个工具什么时候用
- 性格层:语气、风格
- 工作模式:普通 Agent / Planner / Worker / Reviewer
- 审批策略:自动执行、危险操作确认、全部确认
- 项目上下文:AGENTS.md / CLAUDE.md / 项目规则
- 记忆和上下文管理规则
参考 claude code,至少存在以下几层,从泄露源码来看有五层了3
显示已折叠代码(26 行)
| |
这里如果用操作系统打比方会很形象,这也是为什么现在说做一个 agent 越来越像做一个操作系统,这里的设计就很像操作系统里的内存分页 + checkpoint + snapshot 了。
context 管理将是 本项目里面可预见最难 最哲学的部分。
工具系统
Fuction calling作为协议,Tool use 是我们实现的能力
每个工具就像个有注释的函数
名字 + 描述 + 参数 schema + 执行函数
模型会输出结构化调用,我们的工具层执行,然后把结果包装进 tool 的消息块返回
如果模型输出多个还要进行并行执行
MCP
用户注册,我们加到提示词里,模型输出后去调用 其实就是做转发
multi agent
上下文隔离、不同的 worker 不同的对话历史、不能让 subagent 继续向下打开 subagent,完成任务返回摘要给主 agent。
记忆模块
短期:对话窗口和压缩在窗口前面的内容
长期:用户偏好、项目事实等,存本地 json 或者嵌入数据库 支撑混合检索能力
项目规则注入
这个了解一下 CLAUDE.md / AGENTS.md ,为了方便迁移和定制做的。
pi——agent runtime 设计参考
刚刚提到的设计是完整的一套,其中值得推敲的细节会非常多。为了让本项目能成为基座型项目,还需要在缩减一下核心设计,这里参考了 pi 这个项目的设计4 ,这个项目最关键的是双层循环机制以及一些抽象解耦,会更适合 core 的设计,而刚刚的全套 ReAct 会更偏向于能力清单。
单独列几个核心的点
Loop 不是简单的 ReAct 循环,而是 双层循环,外层 followup+内层 turn/tool/steer,这样说比较抽象,但是对于现在使用惯了 claude code 和 codex 的朋友可能不陌生接下来的功能描述
双循环和插嘴
双循环解决的问题其实就是 中途追加对话和队列对话。 比如 agent 正在思考分析代码。此时我补一句:别碰代码,先读。 会在本轮内循环 assistant turn 或者工具结束后追加上下文,重复内循环 follow up 就是 queue message,也就是本循环 agent 大循环结束后追加任务
这个设计思路对于我们系统来讲是需要知道的,这和完全结束追加一条消息本身的含义不同。
Agent Message 和 LLM Message 分离
Agent 平台可以有丰富状态,但不会污染模型协议。以后换 OpenAI、Anthropic、Gemini、本地模型,只改 adapter,不改 core。
tool + before/after hook + execution mode
对于工具本身来讲,它只描述
| |
而加上这个 hook 才实现:权限检查、审批、拦截、危险阻断、审计等
而 execution mode 是分并行和串行,前面有提到,一些工具调用是可以并行的,比如读文件 但是执行 shell、写文件、还是依赖前后顺序的,就需要串行执行
core 不强绑定 memory,而是抽象出来
短期记忆就是 session messages。长期记忆、RAG、用户偏好、项目事实,都不要成为 core 的硬依赖,而是 runtime/plugin 层能力。
这样依赖 agent 可以使用不同的 memory backend,可以扩展使用 json / postgres / vector DB
core 偏单 Agent runtime,multi-agent 放上层编排
单 Agent core 应该只管一件事:
给定 context + tools + model,稳定跑完一个 Agent loop
这样设计 core 不膨胀,也不会把循环搞复杂
我觉得很核心的 事件系统
Agent 运行不是一次函数调用,它是一个过程:
| |
这些事件就是 runtime 的事实来源。
UI 可以用它做流式展示;持久化层可以用它写 event log;审计系统可以记录谁调用了什么工具;计费系统可以统计 token 和工具耗时;扩展系统可以监听某个事件触发动作。
我们做的 PAAS 甚至需要 event log 来 恢复 agent session。
设计第一版本 TODO 和结构
这个就放到下一期讲
相关参考文档/协议/项目
相关技术栈的推荐:LangGraph,虽然在我开发本 agent 产品里应该不会用到它,实在是对 Langchain 有足够的心理阴影。
新兴协议与标准
- 模型上下文协议 (MCP, Model Context Protocol):旨在标准化 Agent 与外部数据源和工具的连接方式。
- 智能体间协议 (A2A, Agent-to-Agent):旨在为不同框架构建的多智能体系统提供一种通用的交互协议。
[2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models ↩︎
[2604.14228] Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems ↩︎
GitHub - earendil-works/pi: AI agent toolkit: coding agent CLI, unified LLM API, TUI & web UI libraries, Slack bot, vLLM pods · GitHub ↩︎